Hibernate обеспечивает использование SQL
-подобного языка Hibernate Query Language
(HQL), который позволяет выполнять SQL-подобные запросы, записанные рядом с объектами данных Hibernate. Запросы критериев
предоставляются как Объектно-ориентированная
альтернатива к HQL.

Добрый день.
В этой статье я хотел бы поделиться своим первым знакомством с такими вещами как Maven, Spring, Hibernate, MySQL и Tomcat в процессе создания простого CRUD приложения. Это третья часть из 4. Статья рассчитана в первую очередь на тех, кто уже прошел здесь 30-40 уровней, но за пределы чистой джавы пока не выбирался и только начинает (или собирается начинать) выходить в открытый мир со всеми этими технологиями, фреймворками и прочими незнакомыми словами.

Это третья часть статьи «Знакомство с Maven, Spring, MySQL, Hibernate и первое CRUD приложение».
Предыдущие части можно увидеть перейдя по ссылкам:
Содержание:

Hibernate 6 была выпущена некоторое время назад, и я вижу, как все больше и больше команд мигрируют свои уровни персистентности или, по крайней мере, готовятся к миграции. Как это часто бывает, объем работы, необходимой для перехода на Hibernate 6, зависит от качества вашего кода и версии Hibernate, которую вы используете в настоящее время.
Для большинства приложений, использующих Hibernate 5, миграция будет относительно быстрой и простой. Но вам придется исправить и обновить некоторые вещи, если вы все еще используете более старую версию Hibernate или некоторые функции, устаревшие в Hibernate 5.
В этой статье я расскажу вам о самых важных шагах по подготовке вашего приложения к миграции и о том, что необходимо сделать при миграции вашего приложения.
У этого термина существуют и другие значения, см. Hibernate
.
Hibernate
— библиотека для языка программирования Java
, предназначенная для решения задач объектно-реляционного отображения ( ORM
), самая популярная реализация спецификации JPA
. Распространяется свободно
на условиях GNU Lesser General Public License
.
Позволяет сократить объёмы низкоуровневого программирования при работе с реляционными базами данных; может использоваться как в процессе проектирования системы классов и таблиц «с нуля», так и для работы с уже существующей базой
.
Библиотека не только решает задачу связи классов Java с таблицами базы данных (и типов данных Java с типами данных SQL
), но и также предоставляет средства для автоматической генерации и обновления набора таблиц, построения запросов и обработки полученных данных и может значительно уменьшить время разработки, которое обычно тратится на ручное написание SQL
— и JDBC
-кода. Hibernate автоматизирует генерацию SQL-запросов и освобождает разработчика от ручной обработки результирующего набора данных и преобразования объектов, максимально облегчая перенос (портирование) приложения на любые базы данных SQL.
Я сталкивался (да и не только я) с проблемой развертывания Hibernate и решил попробовать осветить данную тему. Hibernate — это популярный framework, цель которого связать ООП и реляционную базу данных. Работа с Hibernate сократит время разработки проекта в сравнении с обычным jdbc.
Для новичка программирования настройка framework часто вызывает затруднения. Помощь комьюнити с освещением базовых проблем поможет начинающим осваивать языки программирования быстрее. Статья предназначена только для начинающих в Java, которые впервые развертывают hibernate. Я развертывал hibernate на базе лицензионной IDEA.
Maven framework для автоматизации сборки проекта на основе POM, позволяющая подключать из интернета зависимости, не скачивая библиотеки в проект. P OM (project object model) -декларативное описание проекта. Копируем название библиотек в xml формате с сайта mvnrepository.com
.
Для начала создаёте структуру проекта maven:
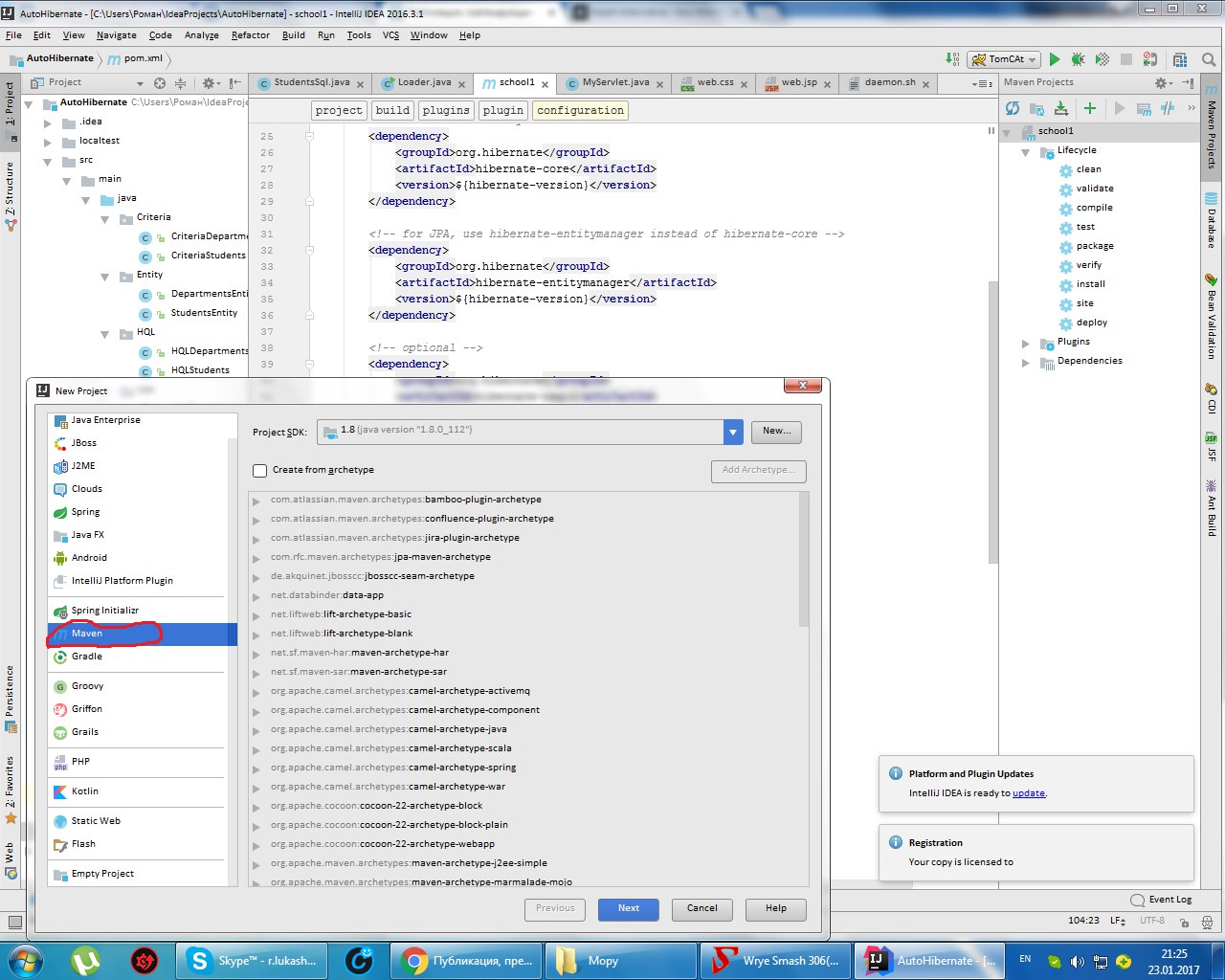
Потом в pom.xml вставляем. Нам понадобятся две зависимости: hibernate-core и mysql-connector, но если вы хотите больше функционала — вы должны подключить больше зависимостей.
Существуют стандартные рекомендации подключать зависимости по отдельности, но я так не делаю.
<properties>
<hibernate-version>5.0.1.Final</hibernate-version>
</properties>
<dependencies>
<!--driver for connection to MYSql database -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.34</version>
</dependency>
<!-- Hibernate -->
<!-- to start need only this -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>${hibernate-version}</version>
</dependency>
<!-- for JPA, use hibernate-entitymanager instead of hibernate-core -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${hibernate-version}</version>
</dependency>
</dependencies>
И щелкаем на Import Changes Enable Auto-Import, автоматически импортируя изменения.
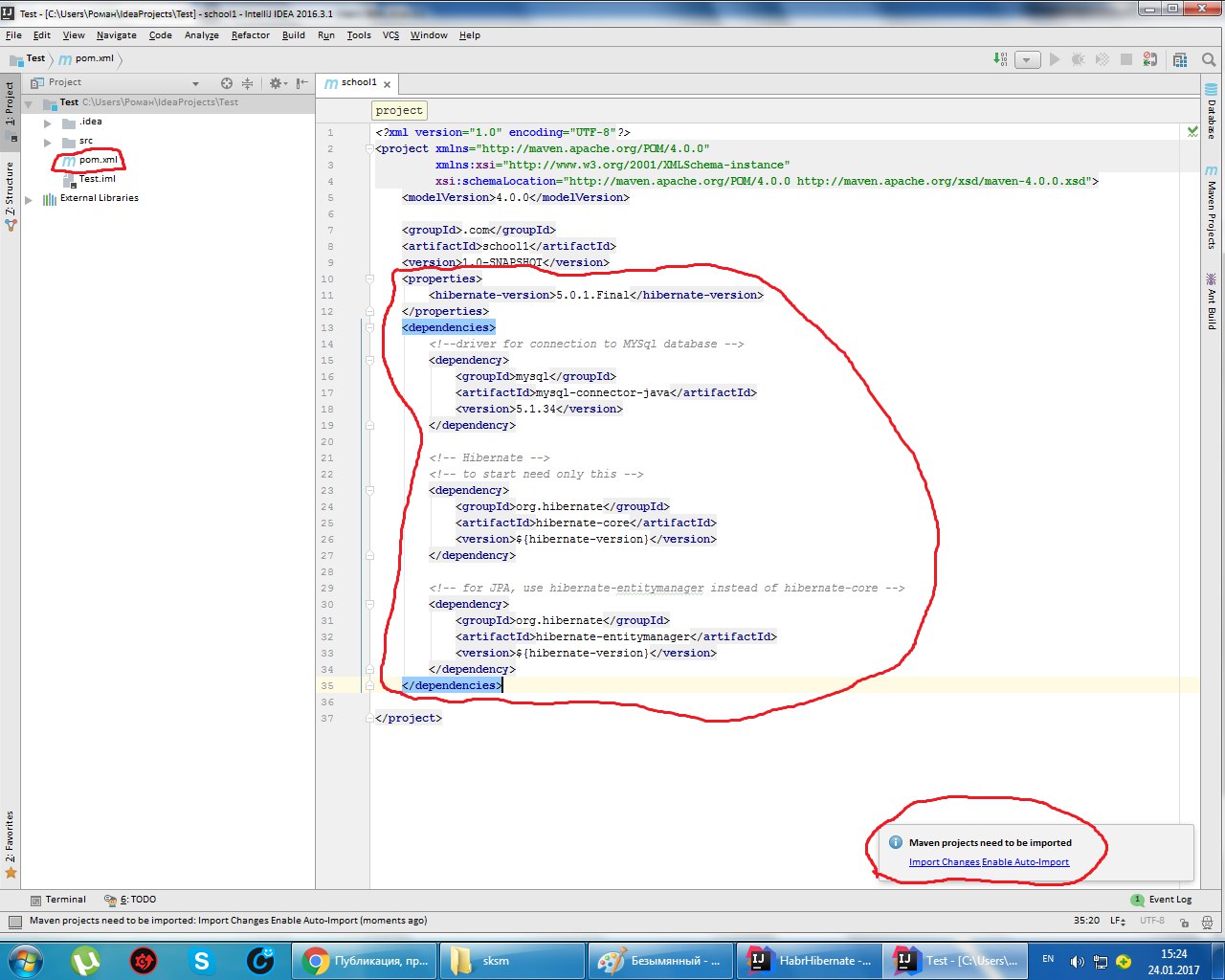
Подключаемся к базе данных, которая развернута на локальном компьютере, выбираем поставщика баз данных MySQL.
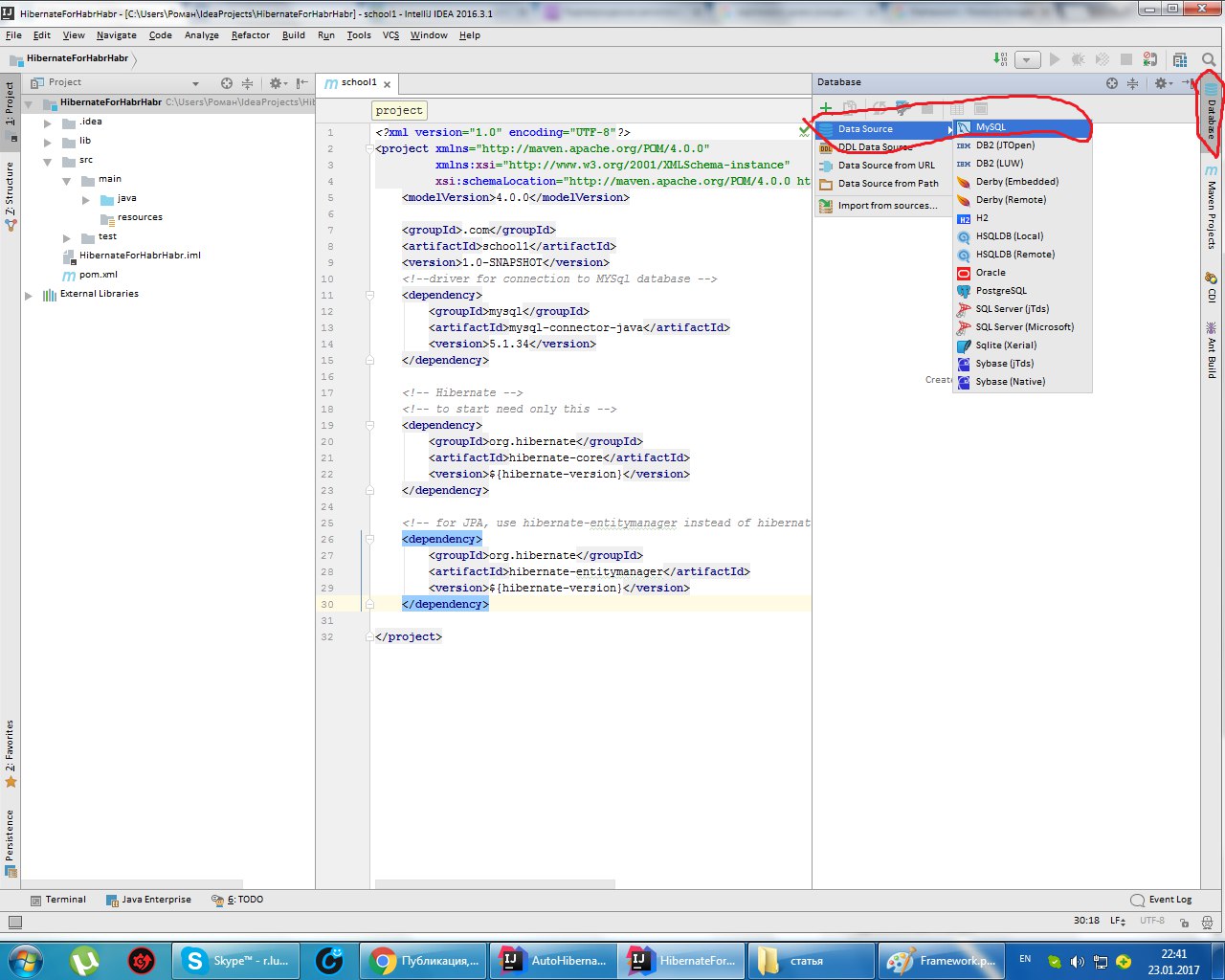
Вводим имя базы данных, имя пользователя и пароль. Протестируйте соединение.
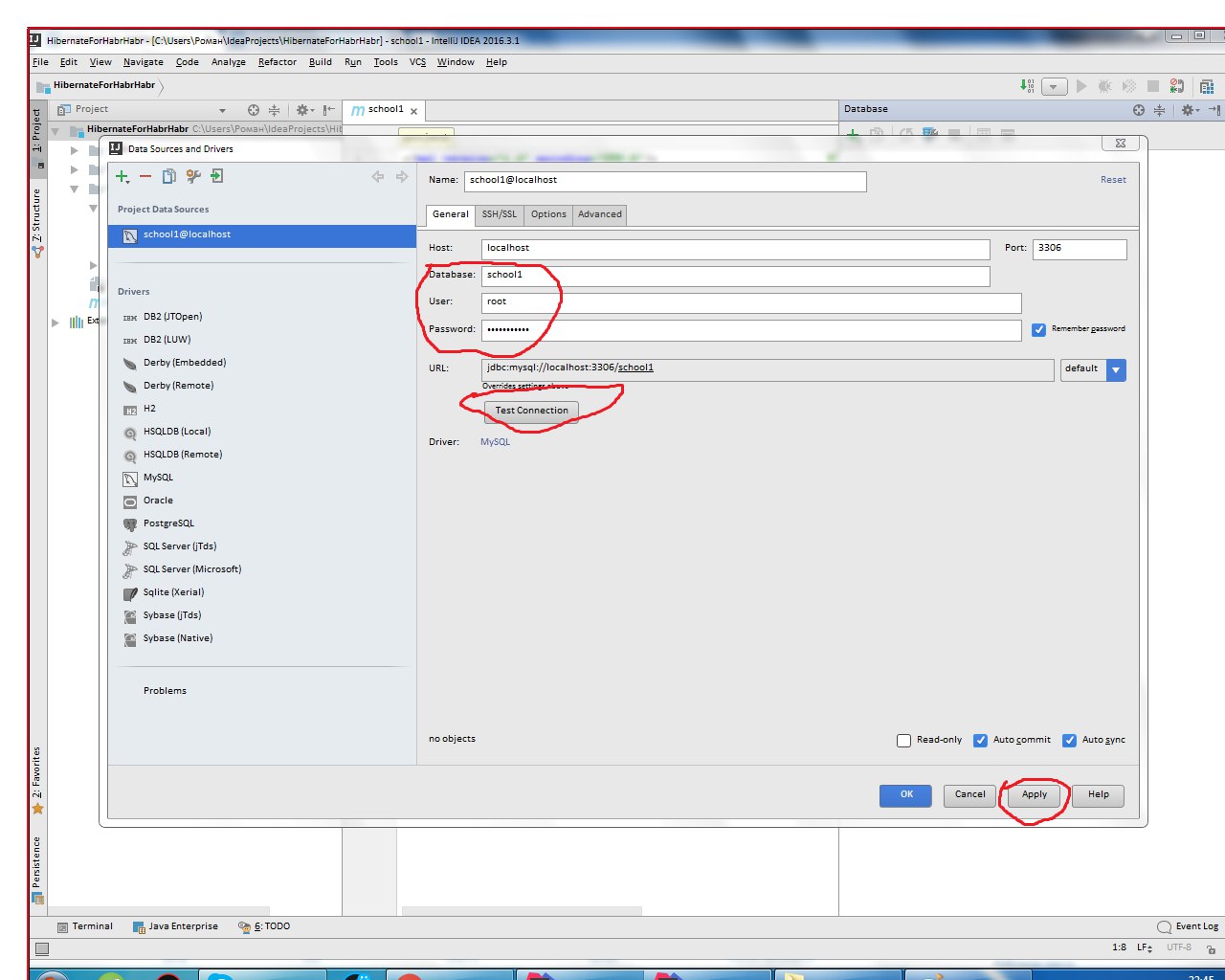
Выбираем проект и через framework support просим у хибернейта создать за нас Entity файлы и классы с Getter и Setter.
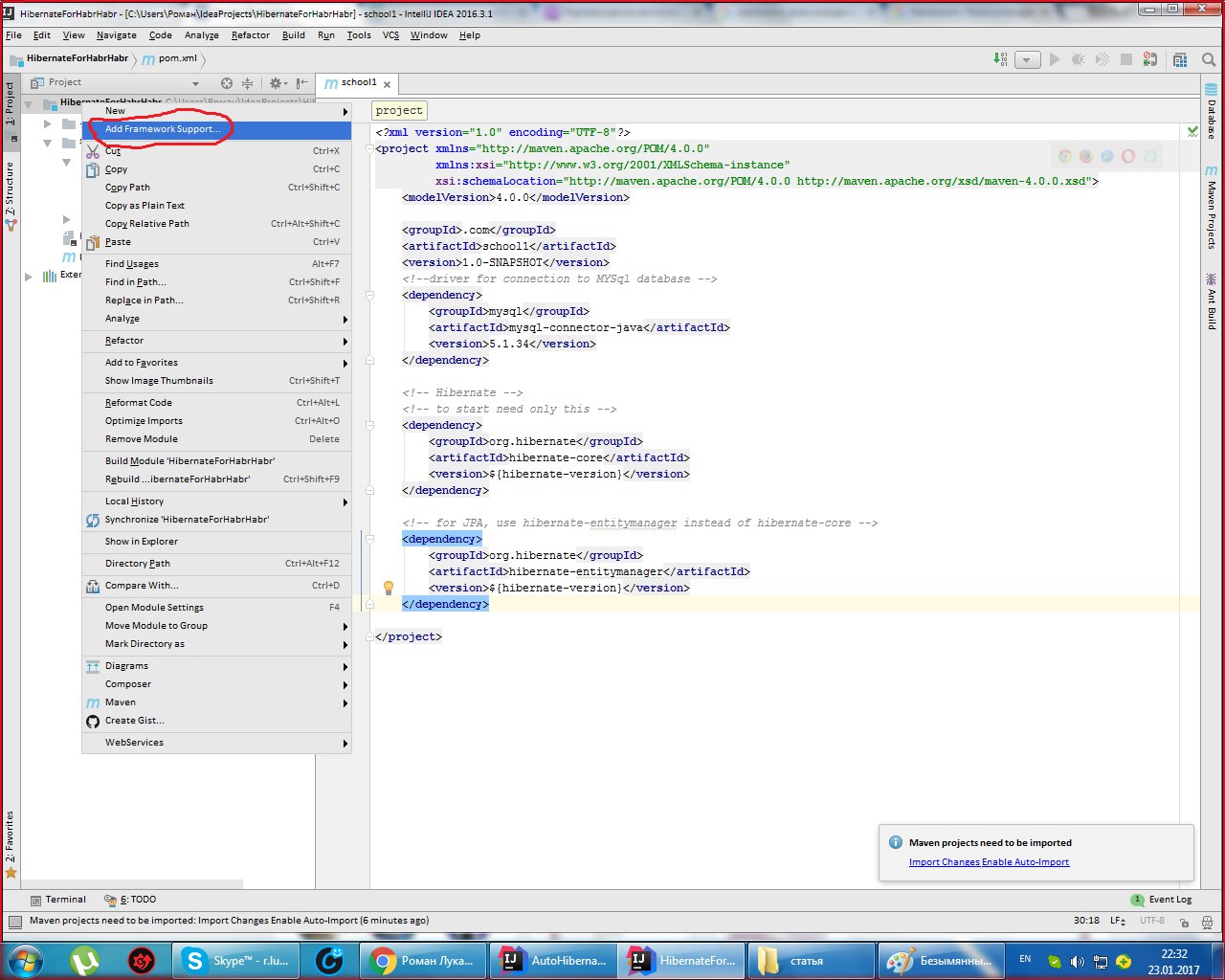
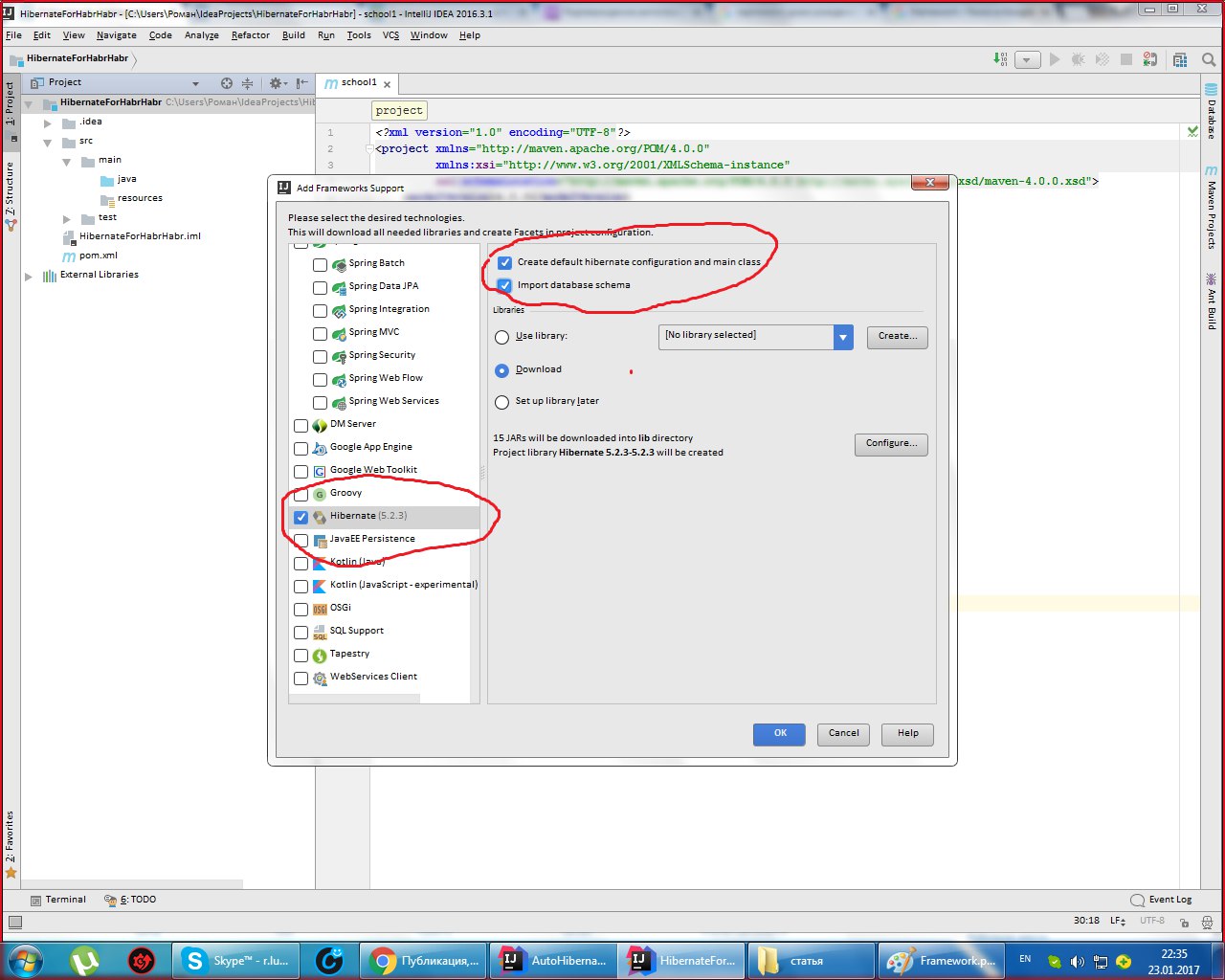
Выбираем Generate Persistence Mapping через кладку Persistence, выбираем jenerate Persistance Mapping, а в появившемся окне прописываем схему базы данных, выбираем prefix и
sufix к автоматически сгенерированным названиям. Будут сгенерированы названия xml файлов и классов с аннотациями:
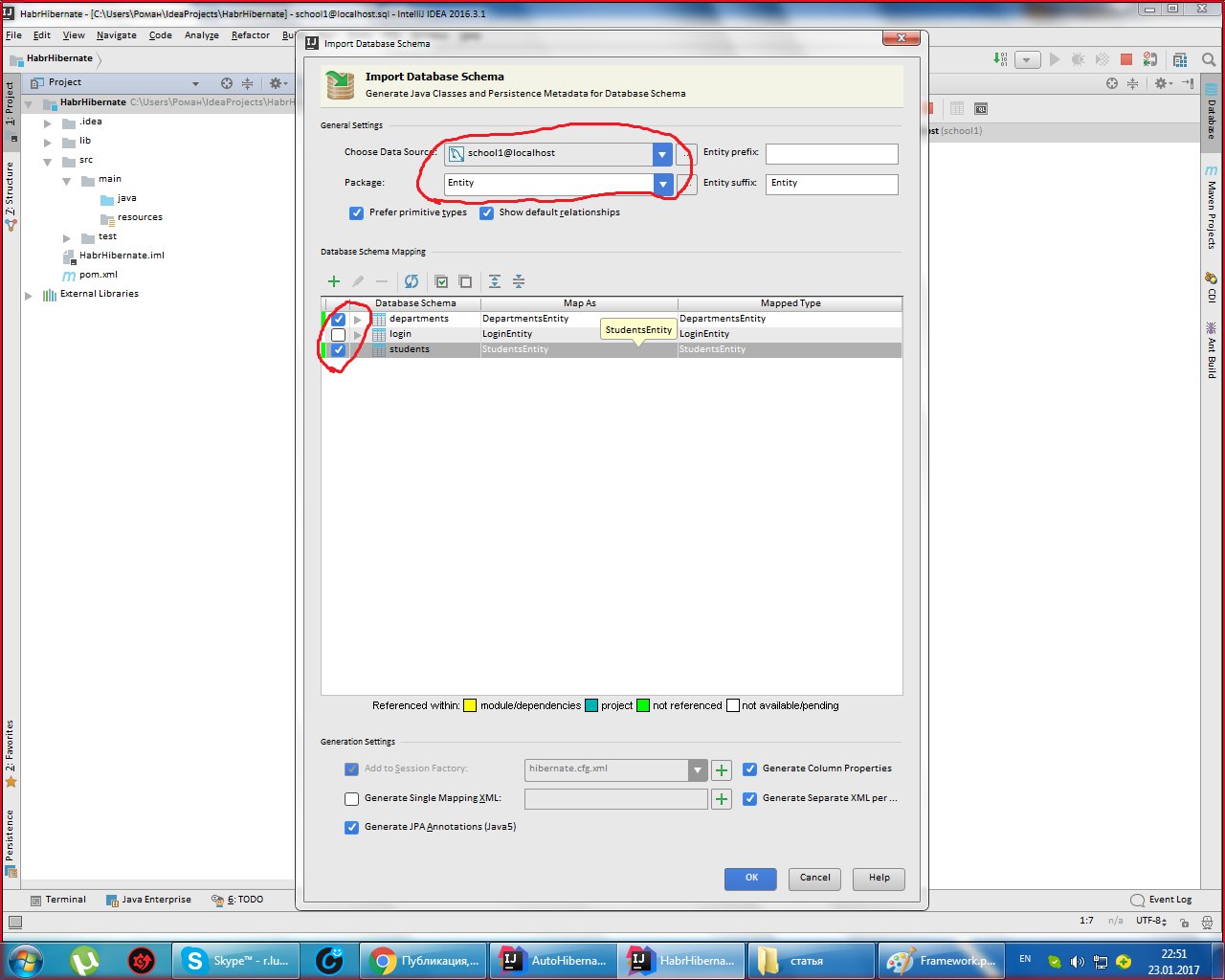
Раскидайте файлы в таком порядке:
.xml-файлы должны находится в папке с ресурсами, а сущности в папке java.
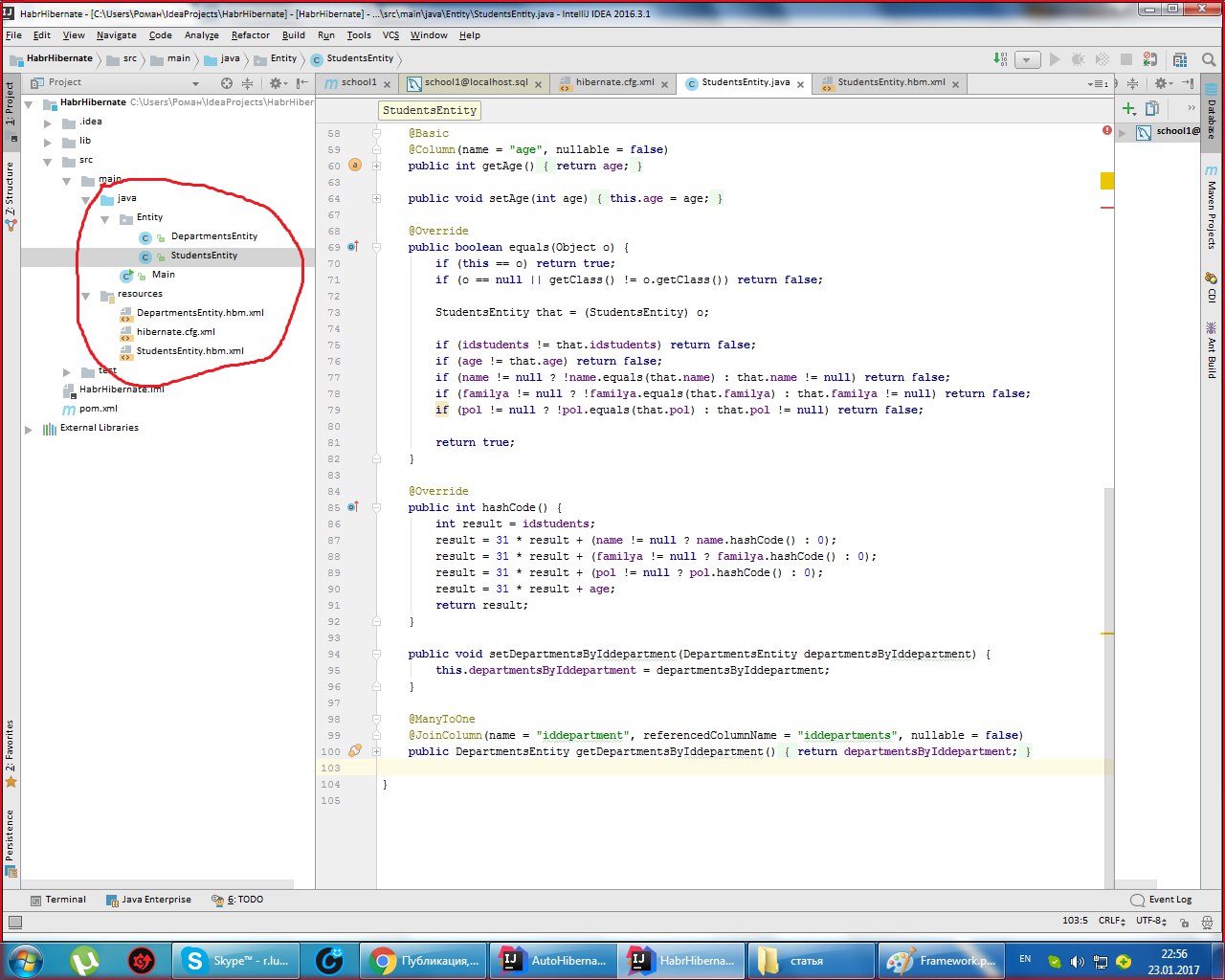
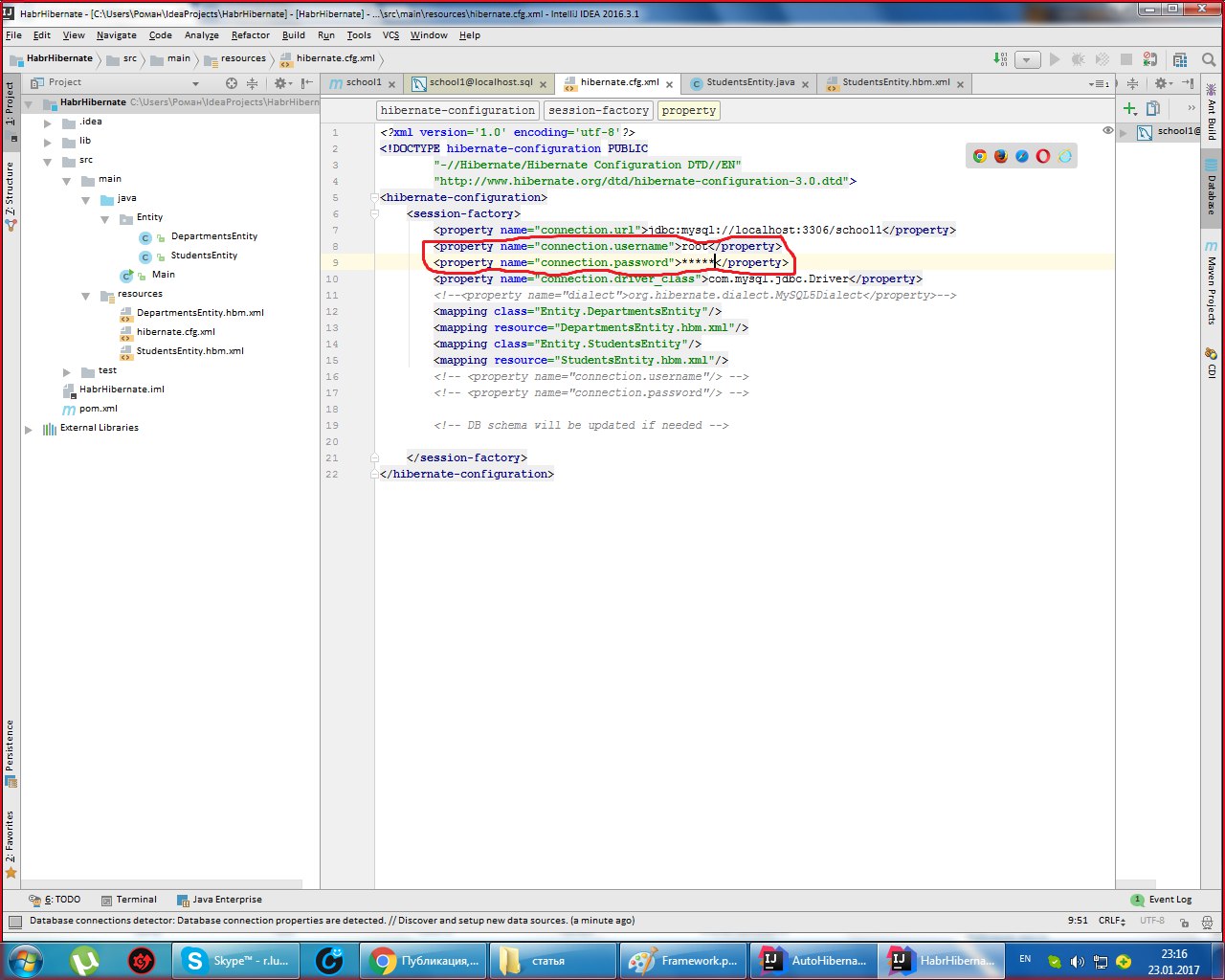
Вот и все! Дальше через класс main запускаем проект.
Это моя первая статья. Рассчитываю на здравую критику.
Создание и подключение базы данных
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.11</version>
</dependency>
Теперь создадим базу данных.
View -> Tool Windows -> Database
— откроется панель базы данных.
New (зеленый +) -> Data Source -> MySQL
— откроется окно, в котором нужно указать имя пользователя и пароль, мы задавали их при установке MySQL (для примера я использовал root и root). Порт (для MySQL по умолчанию 3306), имя и т.д. оставляем как есть. Можно проверить соединение кнопкой » Test Connection
«.

Жмем ОК
и вот мы подключились к серверу MySQL.
Далее создадим базу данных. Для этого можно в открывшейся консоли написать скрипт:
CREATE DATABASE test
Жмем Execute
и база данных готова, теперь ее можно подключить, для этого возвращаемся в Data Source Properties и в поле Database вводим имя базы (test), затем снова вводим имя пользователя с паролем и жмем ОК.
Теперь нужно сделать таблицу. Можно использовать графические инструменты, но для первого раза, пожалуй, стоит ручками написать скрипт, посмотреть хоть как оно выглядит:
USE test;
CREATE TABLE films
(
id int PRIMARY KEY AUTO_INCREMENT,
title VARCHARAUTO_INCREMENT NOT NULL,
year int,
genre VARCHAR,
watched BIT DEFAULT false NOT NULL
)
COLLATE='utf8_general_ci';
CREATE UNIQUE INDEX films_title_uindex ON films (title);
INSERT INTO `films` (`title`,`year`,`genre`, watched)
VALUES
("Inception", 2010, "sci-fi", 1),
("The Lord of the Rings: The Fellowship of the Ring", 2001, "fantasy", 1),
("Tag", 2018, "comedy", 0),
("Gunfight at the O.K. Corral", 1957, "western", 0),
("Die Hard", 1988, "action", 1);
Создается таблица с названием films
со столбцами id
, title
и т.д. Для каждого столбца указывается тип (в скобках максимальный размер вывода).
-
PRIMARY KEY
— это первичный ключ, служит для однозначной идентификации записи в таблице (что подразумевает уникальность) -
AUTO_INCREMENT
— значение будет генерироваться автоматически (само собой оно будет ненулевое, так что это можно не указывать) -
NOT NULL
— тут тоже все очевидно, не может быть пустым -
DEFAULT
— установить значение по-умолчанию -
COLLATE
— кодировка -
CREATE UNIQUE INDEX
— сделать поле уникальным -
INSERT INTO
— добавить запись в таблицу
В результате получилась вот такая табличка:

Пожалуй, стоит попробовать подключиться к ней, пока что просто так, отдельно от нашего веб-приложения. Вдруг какие-то косяки возникнут с этим, тогда сразу разберемся. А то позже будем Hibernate
подключать, делать что-то, настраивать, ковырять, и если там где-то накосячим, то хоть будем знать что проблема не тут.
Ну и чтобы проверить соединение создадим метод main
, временно. Его, в принципе, куда угодно можно засунуть, хоть в класс контроллера, хоть модели или конфигурации, без разницы, нужно просто убедиться с его помощью что все нормально с соединением и можно его удалять. Но чтоб было аккуратнее создадим для него отдельный класс Main
:
package testgroup.filmography;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class Main {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/test";
String username = "root";
String password = "root";
System.out.println("Connecting...");
try (Connection connection = DriverManager.getConnection(url, username, password)) {
System.out.println("Connection successful!");
} catch (SQLException e) {
System.out.println("Connection failed!");
e.printStackTrace();
}
}
}
Тут все просто, задаем параметры подключения к нашей БД и пытаемся создать соединение. Запускаем этот main
и смотрим.
Итак, у меня выскочило исключение, какие-то проблемы с часовым поясом, и еще какое-то предупреждение насчет SSL. Погуляв по просторам интернета можно выяснить, что это достаточно распространенная проблема, причем при использовании разных версий драйвера (mysql-connector-java) может ругаться по-разному. К примеру, опытным путем я выяснил, что при использовании версии 5.1.47 исключений из-за часового пояса нет, соединение нормально создается, только все равно выскакивает предупреждение SSL. Еще с какими-то версиями вроде было что и по поводу SSL было исключение, а не просто предупреждение.
Ну ладно, не суть. Можно отдельно попробовать разобраться с этим вопросом, но сейчас не будем в это углубляться. Решается это все довольно просто, нужно указать в url
дополнительные параметры, а именно serverTimezone
, если проблема с часовым поясом, и useSSL
, если проблема с SSL:
String url = "jdbc:mysql://localhost:3306/test?serverTimezone=Europe/Minsk&useSSL=false";
Теперь мы задали часовой пояс и отключили SSL. Снова запускаем main
и вуаля — Connection successful!
Ну что ж, отлично, как создавать соединение разобрались. Класс Main
свою задачу в принципе выполнил, можно его удалять.
- Hibernate ORM 6.2.6. Final released
- Рекомендации по использованию методов equals()
и hashCode()
в Hibernate
Дата обращения: 20 августа 2009.
Архивировано
6 декабря 2003 года.
- О причине смены названия Hibernate Core -> Hibernate ORM
. Дата обращения: 5 марта 2015.
Архивировано
18 марта 2015 года.
- HIBERNATE - Relational Persistence for Idiomatic Java
(недоступная ссылка — история
)
. J Boss Community. Архивировано
17 февраля 2012 года.
- (недоступная ссылка — история
)
. J Boss Community. Архивировано
17 февраля 2012 года.
- (недоступная ссылка — история
)
. J Boss Community. Архивировано
17 февраля 2012 года.
- Hibernate Envers – Easy Entity Auditing
(недоступная ссылка — история
)
. J Boss Community. Архивировано
17 февраля 2012 года.
- (недоступная ссылка — история
)
. J Boss Community. Архивировано
17 февраля 2012 года.
- Гловер, Эндрю.
Java development 2.0: Вторая волна разработки Java-приложений: Шардинг средствами Hibernate Shards
(недоступная ссылка — история
)
(27 февраля 2012). Архивировано
19 июля 2013 года.
- Hibernate Metamodel Generator
(недоступная ссылка — история
)
. J Boss Community. Архивировано
17 февраля 2012 года.
Конфигурация Hibernate
Перейдем к настройке конфигурации. Создадим в пакете config
класс HibernateConfig
:
package testgroup.filmography.config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
import org.springframework.core.env.Environment;
import org.springframework.jdbc.datasource.DriverManagerDataSource;
import org.springframework.orm.hibernate5.HibernateTransactionManager;
import org.springframework.orm.hibernate5.LocalSessionFactoryBean;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import javax.sql.DataSource;
import java.util.Properties;
@Configuration
@ComponentScan(basePackages = " testgroup.filmography")
@EnableTransactionManagement
@PropertySource(value = "classpath:db.properties")
public class HibernateConfig {
private Environment environment;
@Autowired
public void setEnvironment(Environment environment) {
this.environment = environment;
}
private Properties hibernateProperties() {
Properties properties = new Properties();
properties.put("hibernate.dialect", environment.getRequiredProperty("hibernate.dialect"));
properties.put("hibernate.show_sql", environment.getRequiredProperty("hibernate.show_sql"));
return properties;
}
@Bean
public DataSource dataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName(environment.getRequiredProperty("jdbc.driverClassName"));
dataSource.setUrl(environment.getRequiredProperty("jdbc.url"));
dataSource.setUsername(environment.getRequiredProperty("jdbc.username"));
dataSource.setPassword(environment.getRequiredProperty("jdbc.password"));
return dataSource;
}
@Bean
public LocalSessionFactoryBean sessionFactory() {
LocalSessionFactoryBean sessionFactory = new LocalSessionFactoryBean();
sessionFactory.setDataSource(dataSource());
sessionFactory.setPackagesToScan("testgroup.filmography.model");
sessionFactory.setHibernateProperties(hibernateProperties());
return sessionFactory;
}
@Bean
public HibernateTransactionManager transactionManager() {
HibernateTransactionManager transactionManager = new HibernateTransactionManager();
transactionManager.setSessionFactory(sessionFactory().getObject());
return transactionManager;
}
}
Тут довольно много всего нового, поэтому лучше всего по каждому пункту дополнительно поискать информацию в разных источниках. Здесь же вкратце пройдемся.
- С
@Configuration
и@ComponentScan
уже разобрались когда делали классWebConfig
. -
@EnableTransactionManagement
— позволяет использоватьTransactionManager
для управления транзакциями. Hibernate работает с БД с помощью транзакций, они нужны чтобы какой-то набор операций выполнялся как единое целое, т.е. если в методе возникнут проблемы с какой-то одной операцией, тогда не выполнятся и все остальные, чтобы не было как в классическом примере с переводом денег, когда операция снятия денег с одного счета свершилась, а операция записи на другой не сработала, в итоге деньги исчезли. -
@PropertySource
— подключение файла свойств, который мы недавно создавали. -
Environment
— для того, чтобы получить свойства изproperty
файла. -
hibernateProperties
— этот метод нужен чтобы представить свойства Hibernate в виде объекта Properties -
DataSource
— используется для создания соединения с БД. Это альтернатива DriverManager
, которой мы использовали ранее, когда создавали для проверки подключения методmain
. В документации сказано, чтоDataSource
использовать предпочтительнее. Так и поступим, естественно не забыв почитать в интернете в чем разница и преимущества. В частности, одним из преимуществ является возможность создания пула соединений Database Connection Pool (DBCP). -
sessionFactory
— для создания сессий, с помощью которых осуществляются операции с объектами-сущностями. Здесь мы устанавливаем источник данных, свойства Hibernate и в каком пакете нужно искать классы-сущности. -
transactionManager
— для настройки менеджера транзакций.
Небольшое замечание насчет DataSource
. В документации сказано, что использовать стандартную реализацию, а именно DriverManagerDataSource
, не рекомендуется, т.к. это только замена нормального пула соединений и в целом подходит только для тестов и всего такого. Для нормального приложения предпочтительнее использовать какую-нибудь DBCP библиотеку.
Ну, для нашего приложения конечно хватит и того, что есть, но для полноты картины, пожалуй, все-таки используем другую реализацию как советуют. Добавим в pom.xml
следующую зависимость:
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-dbcp</artifactId>
<version>9.0.10</version>
</dependency>
И в методе dataSource
класса HibernateConfig
заменим DriverManagerDataSource
на BasicDataSource
из пакета org.apache.tomcat.dbcp.dbcp2
:
BasicDataSource dataSource = new BasicDataSource();
Ну вроде все, конфигурация готова, осталось добавить ее в наш AppInitializer
:
protected Class<?>[] getRootConfigClasses() {
return new Class[]{HibernateConfig.class};
}
Слой доступа к данным
Пришло время заняться наконец нашим DAO. Переходим в класс FilmDAOImpl
и первым делом удаляем оттуда пробный список, он нам больше не нужен. Добавляем фабрику сессий и будем работать через нее.
private SessionFactory sessionFactory;
@Autowired
public void setSessionFactory(SessionFactory sessionFactory) {
this.sessionFactory = sessionFactory;
}
Для начала сделаем метод для отображения страницы со списком фильмов, в нем мы будем получать сессию и делать запрос к бд (вытаскивать все записи и формировать список):
public List<Film> allFilms() {
Session session = sessionFactory.getCurrentSession();
return session.createQuery("from Film").list();
}
@Transactional
public List<Film> allFilms() {
return filmDAO.allFilms();
}
Так, тут все готово, в контроллере вроде ничего трогать не нужно. Ну что ж, похоже настал момент истины, жмем Run
и смотрим что получится.

И вот она наша табличка, и на этот раз полученная не из списка, который мы сами же сделали прямо в классе, а из базы данных. Замечательно, похоже все работает. Теперь таким же макаром делаем все остальные CRUD операции с помощью методов сессии. В результате класс выглядит так:
package testgroup.filmography.dao;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import testgroup.filmography.model.Film;
import java.util.List;
@Repository
public class FilmDAOImpl implements FilmDAO {
private SessionFactory sessionFactory;
@Autowired
public void setSessionFactory(SessionFactory sessionFactory) {
this.sessionFactory = sessionFactory;
}
@Override
@SuppressWarnings("unchecked")
public List<Film> allFilms() {
Session session = sessionFactory.getCurrentSession();
return session.createQuery("from Film").list();
}
@Override
public void add(Film film) {
Session session = sessionFactory.getCurrentSession();
session.persist(film);
}
@Override
public void delete(Film film) {
Session session = sessionFactory.getCurrentSession();
session.delete(film);
}
@Override
public void edit(Film film) {
Session session = sessionFactory.getCurrentSession();
session.update(film);
}
@Override
public Film getById(int id) {
Session session = sessionFactory.getCurrentSession();
return session.get(Film.class, id);
}
}
Миграция на Hibernate 6
После реализации изменений, описанных в предыдущем разделе, ваша миграция в Hibernate 6 должна быть простой и потребовать лишь нескольких изменений конфигурации.
Имена последовательностей по умолчанию
Генерация уникальных значений первичных ключей - это первое, что вы должны проверить после миграции вашего уровня персистентности на Hibernate 6. Вам нужно внести небольшое изменение, если вы используете последовательности базы данных и не указываете последовательность для каждой сущности.
Здесь показан пример сущности Author
, в которой задана только стратегия генерации последовательности
, но не указано, какую последовательность должен использовать Hibernate. В таких ситуациях Hibernate использует последовательность по умолчанию.
@Entity
public class Author {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
...
}
В версиях 4 и 5 Hibernate использовала одну последовательность по умолчанию для всей единицы персистентности. Она называлась hibernate_sequence
.
08:18:36,724 DEBUG [org.hibernate.SQL] -
select
nextval('hibernate_sequence')
08:18:36,768 DEBUG [org.hibernate.SQL] -
insert
into
Author
(firstName, lastName, version, id)
values
(?, ?, ?, ?)
Как я показал в недавней статье
, Hibernate 6 изменила этот подход. По умолчанию он использует отдельную последовательность для каждого класса сущностей. Имя этой последовательности состоит из имени сущности и постфикса _SEQ
.
08:24:21,772 DEBUG [org.hibernate.SQL] -
select
nextval('Author_SEQ')
08:24:21,778 WARN [org.hibernate.engine.jdbc.spi.SqlExceptionHelper] - SQL Error: 0, SQLState: 42P01
08:24:21,779 ERROR [org.hibernate.engine.jdbc.spi.SqlExceptionHelper] - ERROR: relation "author_seq" does not exist
Position: 16
Такой подход хорош, и многие разработчики будут чувствовать себя с ним более комфортно. Но он нарушает работу существующих приложений, потому что последовательности, специфические для сущности не существуют в базе данных.
У вас есть два варианта решения этой проблемы:
Обновить схему базы данных
, чтобы добавить новые последовательности.Добавить параметр конфигурации, чтобы указать Hibernate на использование старых последовательностей по умолчанию.
При работе над миграцией я рекомендую использовать 2-й подход. Это самый быстрый и простой способ решить проблему, и вы все равно сможете добавить новые последовательности в будущем релизе.
Вы можете указать Hibernate использовать старые последовательности по умолчанию, настроив свойство hibernate.id.db_structure_naming_strategy
в вашем persistence.xml
. Установив это значение в single
, вы получите последовательности по умолчанию, используемые Hibernate <5.3. А конфигурационное значение legacy
позволяет получить имена последовательностей по умолчанию, используемые Hibernate >=5.3.
<persistence>
<persistence-unit name="my-persistence-unit">
...
<properties>
<! – ensure backward compatibility – >
<property name="hibernate.id.db_structure_naming_strategy" value="legacy" />
...
</properties>
</persistence-unit>
</persistence>
Я объяснил все это более подробно в своем руководстве по стратегиям именования последовательностей, используемым в Hibernate 6
.
Отображения Instant и Duration
Еще одно изменение, которое можно легко не заметит до тех пор, пока развертывание перенесенного слоя персистентности не даст сбой, - это отображение Instant и Duration
.
Когда Hibernate ввела проприетарное отображение для этих типов в версии 5, он отображал Instant
на SqlType. TIMESTAMP
и Duration
на Types. BIGINT
. Переход на Hibernate 6 изменяет это отображение. Теперь он отображает Instant
на SqlType. TIMESTAMP_UTC
и Duration
на SqlType. INTERVAL_SECOND
.
Эти новые отображения кажутся более подходящими, чем старые. Поэтому хорошо, что они изменили их в Hibernate 6. Но это по-прежнему нарушает отображение таблиц в существующих приложениях. Если вы столкнетесь с этой проблемой, вы можете установить свойство конфигурации hibernate.type.preferred_instant_jdbc_type
в TIMESTAMP
и hibernate.type.preferred_duration_jdbc_type
в BIGINT
.
<persistence>
<persistence-unit name="my-persistence-unit">
<properties>
<! – ensure backward compatibility – >
<property name="hibernate.type.preferred_duration_jdbc_type" value="BIGINT" />
<property name="hibernate.type.preferred_instant_jdbc_type" value="TIMESTAMP" />
...
</properties>
</persistence-unit>
</persistence>
Это два новых параметра конфигурации, введенные в Hibernate 6. Оба они помечены как инкубационные
. Это означает, что они могут измениться в будущем. Поэтому я рекомендую вам использовать их во время перехода на Hibernate 6 и вскоре после этого скорректировать модель таблицы так, чтобы она соответствовала новому стандартному отображению Hibernate.
Новые категории ведения журнала
Если вы читали некоторые из моих предыдущих статей о Hibernate 6, вы должны знать, что команда Hibernate переписала код, генерирующий операторы запросов. Одним из побочных эффектов этого изменения стало небольшое изменение в конфигурации ведения журнала.
В Hibernate 5 необходимо активировать ведение журнала трассировки для категории org.hibernate.type.descriptor.sql
, чтобы регистрировать все значения параметров привязки и значения, извлеченные из результирующего набора.
<Configuration>
...
<Loggers>
<Logger name="org.hibernate.SQL" level="debug"/>
<Logger name="org.hibernate.type.descriptor.sql" level="trace"/>
...
</Loggers>
</Configuration>
19:49:20,330 DEBUG [org.hibernate.SQL] -
select
this_.id as id1_0_1_,
this_.firstName as firstnam2_0_1_,
this_.lastName as lastname3_0_1_,
this_.version as version4_0_1_,
books3_.authors_id as authors_2_2_,
book1_.id as books_id1_2_,
book1_.id as id1_1_0_,
book1_.publisher_id as publishe4_1_0_,
book1_.title as title2_1_0_,
book1_.version as version3_1_0_
from
Author this_
inner join
Book_Author books3_
on this_.id=books3_.authors_id
inner join
Book book1_
on books3_.books_id=book1_.id
where
book1_.title like ?
19:49:20,342 TRACE [org.hibernate.type.descriptor.sql.BasicBinder] - binding parameter [1] as [VARCHAR] - [%Hibernate%]
19:49:20,355 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([id1_1_0_] : [BIGINT]) - [1]
19:49:20,355 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([id1_0_1_] : [BIGINT]) - [1]
19:49:20,359 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([publishe4_1_0_] : [BIGINT]) - [1]
19:49:20,359 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([title2_1_0_] : [VARCHAR]) - [Hibernate]
19:49:20,360 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([version3_1_0_] : [INTEGER]) - [0]
19:49:20,361 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([firstnam2_0_1_] : [VARCHAR]) - [Max]
19:49:20,361 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([lastname3_0_1_] : [VARCHAR]) - [WroteABook]
19:49:20,361 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([version4_0_1_] : [INTEGER]) - [0]
19:49:20,361 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([id1_1_0_] : [BIGINT]) - [1]
19:49:20,362 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([id1_0_1_] : [BIGINT]) - [3]
19:49:20,362 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([firstnam2_0_1_] : [VARCHAR]) - [Paul]
19:49:20,362 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([lastname3_0_1_] : [VARCHAR]) - [WritesALot]
19:49:20,362 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([version4_0_1_] : [INTEGER]) - [0]
В Hibernate 6 введена отдельная категория ведения журнала для значений параметров привязки (bind). Вы можете активировать ведение журнала этих значений, настроив ведение журнала трассировки для категории org.hibernate.orm.jdbc.bind
.
<Configuration>
...
<Loggers>
<Logger name="org.hibernate.SQL" level="debug"/>
<Logger name="org.hibernate.orm.jdbc.bind" level="trace"/>
...
</Loggers>
</Configuration>
19:52:11,012 DEBUG [org.hibernate.SQL] -
select
a1_0.id,
a1_0.firstName,
a1_0.lastName,
a1_0.version
from
Author a1_0
join
(Book_Author b1_0
join
Book b1_1
on b1_1.id=b1_0.books_id)
on a1_0.id=b1_0.authors_id
where
b1_1.title like ? escape ''
19:52:11,022 TRACE [org.hibernate.orm.jdbc.bind] - binding parameter [1] as [VARCHAR] - [%Hibernate%]
Hibernate может использоваться как в самостоятельных приложениях Java
, так и в программах Java EE
, выполняемых на сервере (например, сервлет
или компоненты EJB
). Также он может включаться как дополнительная возможность к другим языкам программирования. Например, Adobe
интегрировал Hibernate в девятую версию ColdFusion
(запускаемый на серверах с поддержкой приложений J2EE
) с уровнем абстракции новых функций и синтаксиса, приложенных к CFML
.
Отображение (, сопоставление, проецирование) Java-классов с таблицами базы данных осуществляется с помощью конфигурационных XML
-файлов или Java-аннотаций
. При использовании файла XML Hibernate может генерировать скелет исходного кода
для классов длительного хранения. В этом нет необходимости, если используется аннотация. Hibernate может использовать файл XML или аннотации для поддержки схемы базы данных
.
Обеспечиваются возможности по организации отношения между классами « один-ко-многим
» и « многие-ко-многим
». В дополнение к управлению связями между объектами Hibernate также может управлять рефлексивными отношениями
, где объект имеет связь «один-ко-многим» с другими экземплярами своего собственного типа данных
.
Hibernate поддерживает отображение пользовательских типов значений. Это делает возможными такие сценарии:
- переопределение типа по умолчанию SQL, Hibernate выбирает при отображении столбца свойства;
- отображение перечисляемого типа
Java на поле базы данных, будто они являются обычными свойствами; - отображение одного свойства в несколько столбцов.
Подготовьте уровень персистентности для Hibernate 6
Не все изменения, внесенные в Hibernate 6, являются обратно совместимыми. К счастью, с большинством из них можно разбираться до выполнения миграции. Это позволит вам внедрить необходимые изменения шаг за шагом, продолжая использовать Hibernate 5. Таким образом, вы избежите поломки вашего приложения и сможете подготовить миграцию в течение нескольких релизов или спринтов.
Обновите до JPA 3
Одним из примеров такого изменения является переход на JPA 3. Эта версия спецификации JPA не принесла никаких новых функций. Но по юридическим причинам все имена пакетов и конфигурационных параметров были переименованы из javax.persistence.*
в jakarta.persistence.*
.
Кроме всего прочего, это изменение влияет на инструкции импорта для всех аннотаций отображения (mapping) и EntityManager
и ломает все слои персистентности. Самый простой способ исправить это - использовать функцию поиска и замены в вашей IDE. Замена всех вхождений javax.persistence
на jakarta.persistence
должна исправить ошибки компилятора и обновить вашу конфигурацию.
Hibernate 6 по умолчанию использует JPA 3, и вы можете выполнить команду поиска и замены как часть миграции. Но я рекомендую изменить зависимость вашего проекта с hibernate-core
на hibernate-core-jakarta
и выполнить это изменение, пока вы все еще используете Hibernate 5.
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core-jakarta</artifactId>
<version>5.6.12.Final</version>
</dependency>
Замените API Criteria в Hibernate
Еще одним важным шагом для подготовки уровня персистентности к Hibernate 6 является замена API Criteria в Hibernate. Этот API был устаревшим с момента первого выпуска Hibernate 5, и вы, возможно, уже заменили его. Но я знаю, что для многих приложений это не так.
Вы можете легко проверить, используете ли вы по-прежнему проприетарный API Criteria от Hibernate, проверив предупреждения об устаревании. Если вы найдете предупреждение об устаревании, сообщающее вам, что метод createCriteria(Class)
устарел, значит, вы все еще используете старый API Hibernate и должны его заменить. К сожалению, вы больше не можете откладывать это изменение. Hibernate 6 больше не поддерживает старый, проприетарный API Criteria.
API Criteria в JPA и Hibernate аналогичны. Они позволяют вам динамически создавать запрос во время выполнения. Большинство разработчиков используют его для создания запроса на основе пользовательского ввода или результата некоторых бизнес-правил. Но даже несмотря на то, что оба API имеют одинаковое название и цели, простого пути миграции не существует.
Единственный выход - удалить Hibernate API Criteria из уровня персистентности Hibernate. Вам необходимо переопределить свои запросы, используя API Criteria от JPA. В зависимости от количества запросов, которые вам нужно заменить, и их сложности, это может занять некоторое время. Hibernate 5 поддерживает оба API Criteria, и я рекомендую вам заменить старые запросы один за другим до перехода на Hibernate 6.
Каждый запрос индивидуален и требует разных шагов для переноса. Это затрудняет оценку того, сколько времени займет такая замена и как ее выполнить. Но некоторое время назад я написал руководство
, объясняющее, как перенести наиболее часто используемые функции запросов из Hibernate в JPA Criteria API.
Определите предложение SELECT для ваших запросов
Для всех операторов запросов, которые вы можете статически определить при реализации приложения, вы, скорее всего, используете JPQL
или специфическое для Hibernate расширение HQL.
При использовании HQL Hibernate может сгенерировать предложение SELECT вашего запроса на основе предложения FROM. В этом случае ваш запрос выбирает все классы сущностей, указанные в предложении FROM. К сожалению, это изменилось в Hibernate 6 для всех запросов, которые объединяют несколько классов сущностей.
// запрос с неявным предложением SELECT
List<Object[]> results = em.createQuery("FROM Author a JOIN a.books b").getResultList();
Таким образом, для оператора запроса в предыдущем фрагменте кода Hibernate сгенерировала предложение SELECT, которое ссылалось на сущности Author
и Book
. Сгенерированный оператор был идентичен следующему.
--запрос, сформированный с использованием Hibernate 5
SELECT a, b FROM Author a JOIN a.books b
Для того же оператора HQL Hibernate 6 генерирует только предложение SELECT, которое выбирает корневой объект вашего предложения FROM. В данном примере он выбирает только объект Author
, но не объект Book
.
--запрос, сформированный с использованием Hibernate 6
SELECT a FROM Author a JOIN a.books
Это изменение не вызывает никаких ошибок компилятора, но создает проблемы в коде, который обрабатывает результат запроса. В лучшем случае у вас есть несколько тестовых примеров, которые обнаружат эти ошибки.
Но я рекомендую добавить предложение SELECT, которое ссылается на сущность Author и Book, пока вы еще используете Hibernate 5. Это ничего не изменит для Hibernate 5, но гарантирует, что вы получите тот же результат запроса при использовании Hibernate 6, что и при использовании Hibernate 5.
// определиение предложения SELECT
List<Object[]> results = em.createQuery("SELECT a, b FROM Author a JOIN a.books b").getResultList();
ORM и JPA
По-хорошему, для лучшего понимания, начинать ознакомление с базами данных лучше по порядку, с самого начала, без всяких там гибернейтов и прочего. Поэтому здесь не лишним будет найти какие-то гайды и сначала попробовать поработать с помощью классов JDBC, ручками писать SQL-запросы ну и все такое. Ну а тут пожалуй сразу перейдем к ORM
модели.
Что же это значит. Об этом конечно опять же желательно почитать отдельно, но я попробую вкратце описать. ORM
(Object-Relational Mapping или объектно-реляционное отображение) — это технология для отображения объектов в структуры реляционных баз данных, ну т.е. чтобы представить наш джава-объект в виде строки таблицы. Благодаря ORM можно не заботиться написанием SQL-скриптов и сосредоточиться на работе с объектами.
Как этим пользоваться. В Java есть еще одна замечательная штука, JPA (Java Persistence API), которая реализует ORM концепцию. J PA — это такая спецификация, она описывает требования к объектам, в ней определены различные интерфейсы и аннотации для работы с БД. J PA является по сути описанием, стандартом. Поэтому есть множество конкретных реализаций, одной из которых (причем одной из самых популярных) является Hibernate, в этом собственно и заключается суть этого фреймворка. Hibernate — реализация спецификации JPA, предназначенная для решения задач объектно-реляционного отображения (ORM).
Надо подключить все это дело к нашему проекту. Кроме того, для того, чтобы наш Spring не стоял себе в сторонке а тоже участвовал во всей этой движухе с базами данных, нужно подключить еще пару модулей, т.к. все что мы получили от зависимости spring-webmvc
для этого уже не достаточно. Нам еще понадобится spring-jdbc
, для работы с базой данных, spring-tx
, для поддержки транзакций, и spring-orm
, для работы с Hibernate. Добавим зависимости в pom.xml
:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>5.1.1.RELEASE</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.3.7.Final</version>
</dependency>
Достаточно этих двух зависимостей. javax.persistence-api
подъедет вместе с hibernate-core
, а spring-jdbc
и spring-tx
вместе со spring-orm
.
- Одна из первых книг по Hibernate, написанная опытным разработчиком из Singlewire Software, работавшим с объектно-ориентированными технологиями задолго до того, как это стало популярным.
- Christian Bauer — участник команды разработки Hibernate, Gavin King — основатель проекта Hibernate, участник экспертной группы EJB 3.0 (JSR 220), руководитель в разработке стандарта Web Beans JSR 299, включающего концепции Hibernate, JSF и EJB 3.0. Книга описывает устаревшую версию Hibernate 2.x. Считается одной из лучших по отзывам критиков
- Фактически это обновлённая и пересмотренная версия книги «Hibernate in Action», здесь описывается Hibernate 3.x и JPA
. Второе издание этой книги, описывающее Hibernate 5, запланировано к выходу в начале 2015 г. (отдельные главы выложены в электронном виде с марта 2013)
- Фактически это обновлённая и пересмотренная версия книги «Hibernate in Action», здесь описывается Hibernate 3.x и JPA
- , .
Beginning Hibernate: From Novice to Professional
. — 3rd ed. — Apress
, 2006, August 25. — 360 p. — ISBN 1-59059-693-5
.
Архивная копия
от 24 декабря 2010 на Wayback Machine
- , .
Beginning Hibernate
. — 2nd ed. — Apress, 2010, May 28. — 400 p. — ISBN 1-4302-2850-4
.
Архивная копия
от 5 декабря 2010 на Wayback Machine
- Официальный сайт Hibernate
(англ.)
Hibernate Validator — аннотации и API для проверки верности и целостности данных
Hibernate Search — интеграция Hibernate с поисковой системой Lucene
, с целью индексирования и поиска данных
Hibernate Tools — средства разработки для Eclipse
и Ant
Entity
Итак, мы хотим, чтобы объекты класса Film
могли быть сохранены в базе данных. Для этого класс должен удовлетворять ряду условий. В JPA для этого есть такое понятие как Сущность (Entity)
. Класс-сущность это обыкновенный POJO
класс, с приватными полями и геттерами и сеттерами для них. У него обязательно должен быть не приватный конструктор без параметров (или конструктор по-умолчанию), и он должен иметь первичный ключ, т.е. то что будет однозначно идентифицировать каждую запись этого класса в БД. Обо всех требованиях к такому классу также можно почитать отдельно. Сделаем наш класс Film
сущностью при помощи JPA аннотаций:
package testgroup.filmography.model;
import javax.persistence.*;
@Entity
@Table(name = "films")
public class Film {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
@Column(name = "title")
private String title;
@Column(name = "year")
private int year;
@Column(name = "genre")
private String genre;
@Column(name = "watched")
private boolean watched;
// + getters and setters
}
-
@Entity
— указывает на то, что данный класс является сущностью. -
@Table
— указывает на конкретную таблицу для отображения этой сущности. -
@Id
— указывает, что данное поле является первичным ключом, т.е. это свойство будет использоваться для идентификации каждой уникальной записи. -
@Column
— связывает поле со столбцом таблицы. Если имена поля и столбца таблицы совпадают, можно не указывать. -
@GeneratedValue
— свойство будет генерироваться автоматически, в скобках можно указать каким образом. Не будем сейчас разбираться как именно работают разные стратегии. Достаточно знать, что в данном случае каждое новое значение будет увеличиваться на 1 от предыдущего.
Можно для каждого свойства еще дополнительно указать много чего еще, например, что должно быть не нулевое, или уникальное, указать значение по-умолчанию, максимальный размер и т.д. Это пригодится если нужно сгенерировать таблицу на основании этого класса, с Hibernate есть такая возможность. Но мы таблицу уже сами создали и все свойства настроили, так что обойдемся без этого.
Небольшое замечание.
В документации Hibernate применять аннотации рекомендуется не к полям, а к геттерам. Однако разница между этими подходами довольно тонкая и в нашем простеньком приложении это никак не повлияет. Кроме того, большинство людей все равно ставят аннотации над полями. Поэтому, оставим так, выглядит аккуратнее.
Свойства Hibernate
jdbc.driverClassName=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/test?serverTimezone=Europe/Minsk&useSSL=false
jdbc.username=root
jdbc.password=root
hibernate.dialect=org.hibernate.dialect.MySQL8Dialect
hibernate.show_sql=true
Ну сверху все понятно, параметры для подключения к бд, т.е. имя класса драйвера, урл, имя пользователя и пароль.
hibernate.dialect
— это свойство нужно для того, чтобы указать Hibernate какой именно вариант языка SQL используется. Дело в том, что в каждой СУБД для того чтобы расширить возможности, добавить какой-то функционал или что-то оптимизировать, обычно слегка модернизируют язык. В результате получается, что у каждой СУБД свой SQL диалект. Это как с английским, вроде язык один, но в Австралии, США или Британии он будет чуть-чуть отличаться, и какие-то слова могут иметь различное значение. И для того, чтобы не было никаких проблем с пониманием, нужно прямо сообщить Hibernate с чем именно ему предстоит иметь дело.
hibernate.show_sql
— благодаря этому свойству в консоли будут отображаться запросы к БД. Это не обязательно, но с этой штукой хоть можно глянуть что происходит, а то иначе может показаться что Hibernate какую-то магию творит. Ну, оно конечно не совсем понятно будет выводить, лучше для этого какой-то логгер использовать, но это как-нибудь в другой раз, пока и так сойдет.
Версия 1.0 выпущена в июле 2002 года, через год вышла версия 2.0, ещё через год — 3.0. В выпуске от 16 октября 2006 появились Hibernate Core, Annotations, Entity Manager (версия 3.2.0. GA с поддержкой JPA
). В декабре 2013 года выпущен Hibernate ORM 4.3.0. В сентябре 2015 выпущен Hibernate ORM 5.0.2.
Коллекции объектов данных, как правило, хранятся в виде коллекций Java-объектов, таких, как набор (Set) и список (List). Поддерживаются обобщенные классы
(Generics), введеные в Java 5. Hibernate может быть настроен на «ленивые» (отложенные) загрузки коллекций. Отложенные загрузки является вариантом по умолчанию, начиная с Hibernate 3.
Связанные объекты могут быть настроены на каскадные
операции. Например, родительский класс Album (музыкальный альбом) может быть настроен на каскадное сохранение и/или удаление своего потомка Track. Это может сократить время разработки и обеспечить целостность
. Функция проверки изменения данных () позволяет избежать ненужной записи действий в базу данных, выполняя SQL-обновление только при изменении полей персистентных объектов.
Успех библиотеки Hibernate подтолкнул JCP
к разработке спецификации JDO, ставшей одной из стандартных технологий ORM на платформе JavaEE. Также Hibernate совместима с JSR-220/317 и предоставляет стандартные средства JPA.
Заключение
В Hibernate 6 было внесено несколько изменений, которые нарушают обратную совместимость. Не все из них требуют огромных изменений в коде вашего уровня персистентности. Возможно, будет достаточно добавить всего несколько параметров конфигурации, чтобы сохранить старое поведение.
Но два изменения потребуют особого внимания. Это обновление до JPA 3 и удаление устаревшего API Criteria из Hibernate. Я рекомендую вам разобраться с обоими изменениями, пока вы все еще используете Hibernate 5.
Обновление до JPA 3 требует, чтобы вы изменили имена параметров конфигурации и инструкции импорта всех классов, интерфейсов и аннотаций, определенных спецификацией. Но не волнуйтесь. Обычно это звучит хуже, чем есть на самом деле. Я перенес несколько проектов, выполнив простую операцию поиска и замены в своей IDE. Обычно это делалось за несколько минут.
Удаление устаревшего API Criteria в Hibernate вызовет более серьезные проблемы. Вам нужно будет переписать все запросы, которые используют старый API. Я рекомендую вам сделать это, пока вы еще используете Hibernate 5. Он по-прежнему поддерживает старый API Criteria от Hibernate и API Criteria от JPA. Таким образом, вы сможете заменять один запрос за другим, не нарушая работу вашего приложения.